
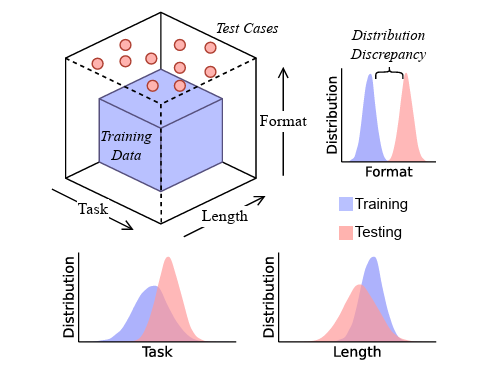
গবেষকরা পরীক্ষার কেসগুলি ব্যবহার করেছেন যা টাস্কের ধরণ, ফর্ম্যাট এবং দৈর্ঘ্যে এলএলএম প্রশিক্ষণের ডেটার বাইরে পড়ে।
এই সরলিকৃত মডেলগুলি তখন বিভিন্ন ধরণের কাজ ব্যবহার করে পরীক্ষা করা হয়েছিল, যার মধ্যে কয়েকটি প্রশিক্ষণের ডেটার ফাংশন নিদর্শনগুলির সাথে সুনির্দিষ্ট বা ঘনিষ্ঠভাবে মেলে এবং অন্যদের যেগুলি প্রশিক্ষণের ডেটার জন্য আংশিক বা সম্পূর্ণ “ডোমেনের বাইরে” ছিল এমন ফাংশন রচনাগুলির প্রয়োজন ছিল। উদাহরণস্বরূপ, দুটি চক্রীয় শিফট দেখানো ডেটাতে প্রশিক্ষিত একটি মডেলকে দুটি পচা শিফট জড়িত একটি অভিনব রূপান্তর করতে বলা যেতে পারে (উভয় শিফটের একক উদাহরণ কেমন দেখায় তার প্রাথমিক প্রশিক্ষণ সহ)। চূড়ান্ত উত্তর এবং যুক্তিযুক্ত পদক্ষেপগুলি ব্যবহার করে পছন্দসই উত্তরের সাথে তুলনা করা হয়েছিল নীল স্কোর এবং লেভেনশেটিন দূরত্ব তাদের নির্ভুলতার একটি উদ্দেশ্যমূলক পরিমাপের জন্য।
গবেষকরা যেমন অনুমান করেছিলেন, প্রশিক্ষণের ডেটাতে সরাসরি প্রদর্শিত হয়নি এমন রূপান্তরগুলির অভিনব সেটগুলি সাধারণীকরণ করতে বলা হলে এই প্রাথমিক মডেলগুলি বিপর্যয়করভাবে ব্যর্থ হতে শুরু করে। যদিও মডেলগুলি প্রায়শই প্রশিক্ষণের ডেটাতে অনুরূপ নিদর্শনগুলির উপর ভিত্তি করে নতুন যৌক্তিক নিয়মগুলি সাধারণীকরণের চেষ্টা করত, এটি প্রায়শই মডেলটিকে “সঠিক যুক্তিযুক্ত পথগুলি, তবুও ভুল উত্তর (গুলি) দেয়” এর দিকে নিয়ে যায়। অন্যান্য ক্ষেত্রে, এলএলএম কখনও কখনও “অবিশ্বস্ত যুক্তিযুক্ত পথ” দিয়ে যুক্ত সঠিক উত্তরগুলিতে হোঁচট খায় যা যৌক্তিকভাবে অনুসরণ করে না।
গবেষকরা লিখেছেন, “পাঠ্যের সত্যিকারের বোঝাপড়া প্রদর্শনের পরিবর্তে, টাস্ক ট্রান্সফর্মেশনের অধীনে খাটের যুক্তি প্রশিক্ষণের সময় শিখে নেওয়া নিদর্শনগুলির একটি প্রতিলিপি প্রতিফলিত করে বলে মনে হয়,” গবেষকরা লিখেছেন।
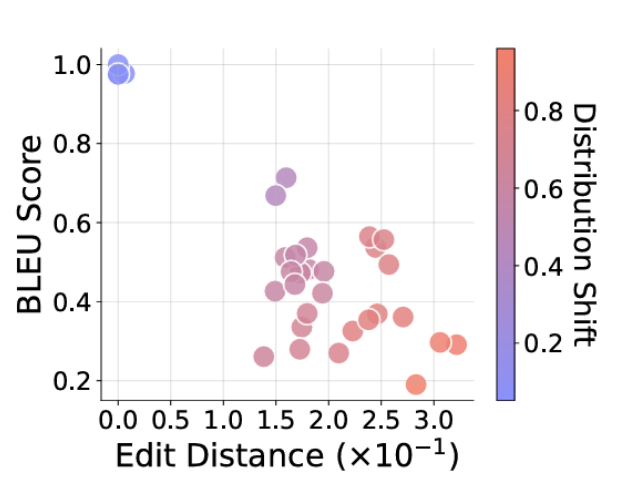
অনুরোধ করা কাজগুলি প্রশিক্ষণ বিতরণের (রেড্ডার ডটস) বাইরে আরও বেশি করে, উত্তরগুলি কাঙ্ক্ষিত উত্তর (গ্রাফের নীচের ডানদিকে) থেকে আরও দূরে প্রবাহ সরবরাহ করে।
গবেষকরা প্রশিক্ষণের ডেটাতে পাওয়াগুলির তুলনায় কিছুটা খাটো বা দীর্ঘতর ইনপুট পাঠ্য স্ট্রিং ব্যবহার করে তাদের নিয়ন্ত্রিত সিস্টেমটি পরীক্ষা করতে গিয়েছিলেন, বা এটি প্রশিক্ষিতদের চেয়ে বিভিন্ন দৈর্ঘ্যের ফাংশন চেইনগুলির প্রয়োজনীয় ফাংশন চেইনগুলি। উভয় ক্ষেত্রেই ফলাফলগুলির যথার্থতা “(দৈর্ঘ্য) তাত্পর্য বাড়ার সাথে সাথে অবনতি ঘটে,” এইভাবে “মডেলগুলিতে সাধারণীকরণের ব্যর্থতা নির্দেশ করে”। পরীক্ষার কার্যগুলির ফর্ম্যাটে ছোট, অপরিচিত-থেকে-মডেল তাত্পর্যগুলি (যেমন, প্রশিক্ষণের ডেটাতে পাওয়া যায় না এমন চিঠি বা প্রতীকগুলির প্রবর্তন) এছাড়াও মডেলটির প্রতিক্রিয়াগুলির “তীব্রভাবে অবনমিত” এবং “প্রভাবিত (সম্পাদনা)” পারফরম্যান্সের কারণ হিসাবে দেখা গেছে, গবেষকরা খুঁজে পেয়েছেন।

